Data Analytics - Data Science

Análise de dados com Python
Objetivos
- Importar bibliotecas e carregar dataset
- Explorar o dataset
- Tratar os dados
- Criação de histogramas
- Criação de boxplots
- Criação de gráficos e análise
- Comparação de médias
- Criação scatterplots: Glucose × BMI e Age × BMI
- Treinar uma regressão logística
- Análise de PCA utilizando 3 parâmetros
TL;DR:
Neste projeto prático de Data Analytics com Python, explorei o dataset Pima Indians Diabetes desde a limpeza de dados e análise exploratória (EDA) até a aplicação de modelos de Machine Learning. Após tratar valores inconsistentes e criar visualizações gráficas para mapear distribuições e outliers, treinei um modelo de Regressão Logística que atingiu 79,3% de acurácia na previsão de diagnósticos. Por fim, uma análise de componentes principais (PCA), criando uma separação clara entre indivíduos saudáveis e diabéticos.
O dataset escolhido para analise: Pima Indians Diabetes Database
Importar bibliotecas e carregar dataset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
'''
1. Importar bibliotecas (pandas, numpy, matplotlib.pyplot e seaborn) e carregar o arquivo
pima_diabetes (fornecido e utilizado nas aulas). Exibir as primeiras linhas com head().
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#Para os últimos exercicios
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
df = pd.read_csv('/content/pima_diabetes.csv')
mostrar_tabela(df.head())
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome |
|---|---|---|---|---|---|---|---|---|
| 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
Explorar o dataset
1
2
3
4
5
6
7
'''
2. Explorar a estrutura do dataset usando info() e describe(). Identificar colunas numéricas
e possíveis valores inválidos.
'''
mostrar_info(df)
mostrar_tabela(df.describe(), incluir_index=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| count | 768 | 768 | 768 | 768 | 768 | 768 | 768 | 768 | 768 |
| mean | 3.84505 | 120.895 | 69.1055 | 20.5365 | 79.7995 | 31.9926 | 0.471876 | 33.2409 | 0.348958 |
| std | 3.36958 | 31.9726 | 19.3558 | 15.9522 | 115.244 | 7.88416 | 0.331329 | 11.7602 | 0.476951 |
| min | 0 | 0 | 0 | 0 | 0 | 0 | 0.078 | 21 | 0 |
| 25% | 1 | 99 | 62 | 0 | 0 | 27.3 | 0.24375 | 24 | 0 |
| 50% | 3 | 117 | 72 | 23 | 30.5 | 32 | 0.3725 | 29 | 0 |
| 75% | 6 | 140.25 | 80 | 32 | 127.25 | 36.6 | 0.62625 | 41 | 1 |
| max | 17 | 199 | 122 | 99 | 846 | 67.1 | 2.42 | 81 | 1 |
Analisando os dados acima com info() e describe(), percebemos que há registros com valores iguais a 0, representando dados faltantes. Os registros com dados faltantes estão nos campos: Glucose, BloodPressure, SkinThickness, Insulin e BMI. Além disso, 25% dos valores de SkinThickness e Insulin estão iguais a 0. Biologicamente uma pessoa viva não pode ter esses valores.
Tratar os dados
1
2
3
4
5
6
7
8
9
10
11
12
13
14
'''
3. Tratar dados: identificar valores zero em colunas onde zero não faz sentido; substituir
por NaN; contar valores ausentes.
'''
#Identificando colunas que possuem zero
#Criamos uma lista com todas as colunas que possuem valores zeros(que não fazem sentido biologicamente)
colunas_com_zeros = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
#Substituir zero por NaN (Not a Number)
df[colunas_com_zeros] = df[colunas_com_zeros].replace(0, np.nan)
#Contando os valores ausentes e exibindo com print.
print(df.isnull().sum())
1
2
3
4
5
6
7
8
9
10
Pregnancies 0
Glucose 5
BloodPressure 35
SkinThickness 227
Insulin 374
BMI 11
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64
Criação de histogramas
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
'''
4. Criar histogramas das variáveis numéricas usando df.hist()
'''
eixos = df.hist(figsize=(15, 15), edgecolor='black', bins=19)
print(type(eixos)) #verificando qual é o tipo da variável.
for x in eixos.flatten():
x.set_xlabel('Valores') #Eixo horizontal
x.set_ylabel('Frequência') #Eixo vertical
coluna_nome = x.get_title()
if coluna_nome in df.columns: #Verificando se a coluna existe
valor_skew = df[coluna_nome].skew() #Calculando o skew para cada coluna.
x.set_title(f"{coluna_nome}\nSkew: {valor_skew:.2f}", fontsize=12, fontweight='bold')
plt.show()
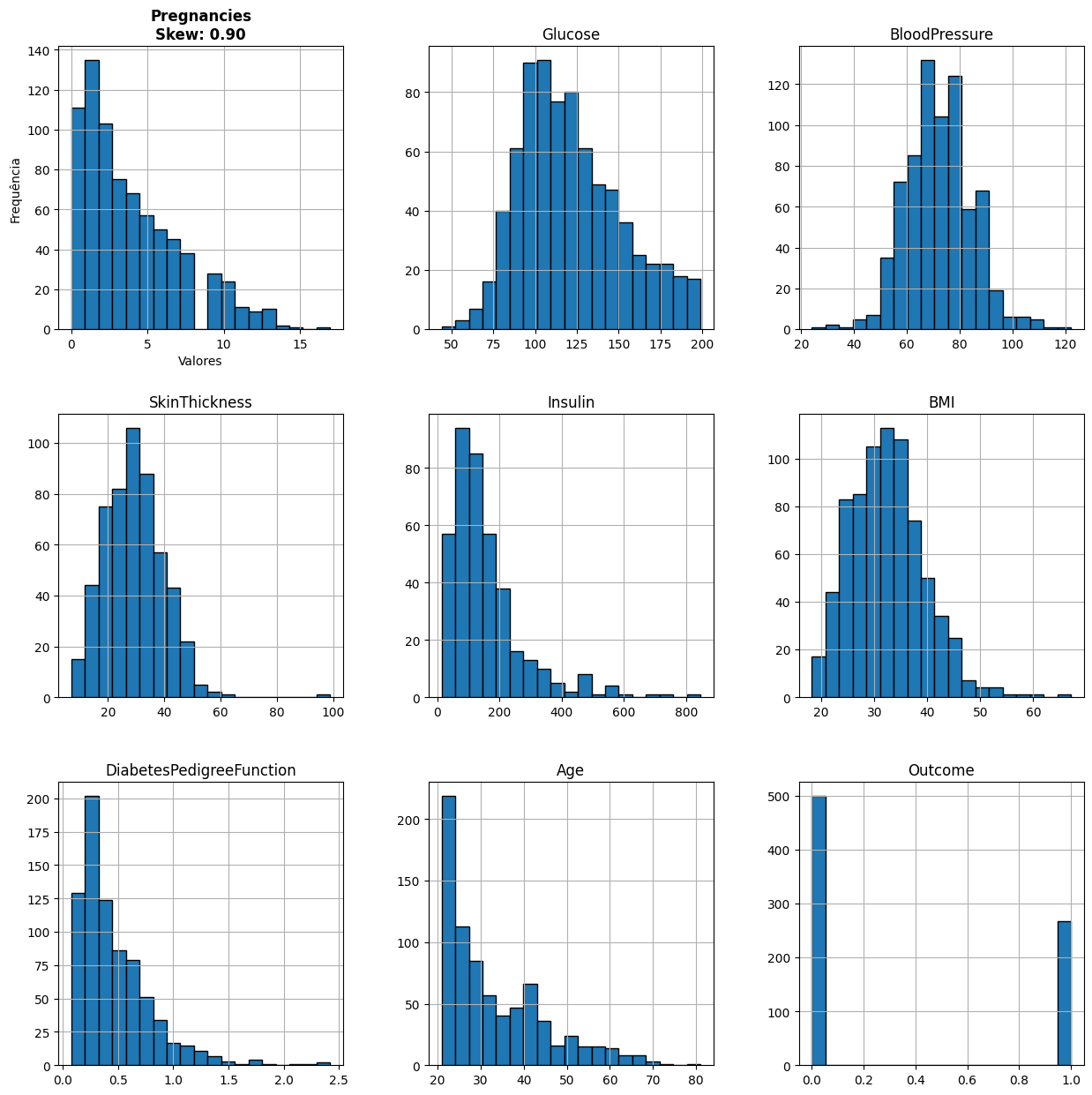
Explicação do código acima.
Com o comando df.hist() criamos o histograma de todas as colunas. Os parâmetros passados para a função hist() são utilizados para definir o layout do gráfico. Salvamos os histogramas em uma variável chamada “eixos”, a função retorna um objeto do tipo numpy.ndarray.
No laço for, definimos para cada gráfico o eixo X (horizontal) e o eixo Y (vertical), com os nomes valores e frequência, respectivamente. Salvamos em uma variável coluna_nome o nome da coluna. Dentro da condição if, verificamos se o dataframe (df) possui o nome da coluna que foi salvo na variável anterior.
Se sim, calculamos o skew da coluna e armazenamos o resultado na variável. Após isso, definimos o título que será exibido no gráfico, inserimos o nome da coluna e seu valor de skew, além de configurarmos o tamanho da fonte (fontsize) e o estilo em negrito para a exibição.
Com o laço for, conseguimos calcular o skew de cada coluna e exibi-lo junto ao gráfico da respectiva coluna.
Identificar distribuições mais assimétricas.
Visualmente, já percebemos que as colunas Pregnancies, SkinThickness, BMI, Insulin e DiabetesPedigreeFunction apresentam diferenças.
Com a definição de NaN que fizemos no exercício anterior, garantimos que os valores que não são válidos não entrem no cálculo do skew().
As distribuições mais assimétricas são: Insulin, DiabetesPedigreeFunction - fortemente assimétrica a esquerda.
Criação de boxplots
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
'''
5. Criar boxplots de Glucose, BMI, Age e BloodPressure para observar outliers.
'''
#Definindo as colunas que iremos criar os boxplots
colunas = ['Glucose', 'BMI', 'Age', 'BloodPressure']
#Com o laço for realizamos o caculo e a geração de boxplots de todas as colunas que definimos.
for coluna_nome in colunas:
if coluna_nome in df.columns:
#Calcular IQR de cada coluna
Q1 = df[coluna_nome].quantile(0.25)
Q3 = df[coluna_nome].quantile(0.75)
IQR = Q3 - Q1
#Abaixo difinimos o intervalo, qualquer valor do dataset que estiver fora do intervalo é um outliers
limite_inf = Q1 - 1.5*IQR
limite_sup = Q3 + 1.5*IQR
#Detectando outliers de cada coluna
outliers = df[(df[coluna_nome] < limite_inf) | (df[coluna_nome] > limite_sup)]
quantidade_outliers = len(outliers) #contando os outliers com função len()
#Geração do Boxplot
plt.figure(figsize=(8, 4))
sns.boxplot(y=df[coluna_nome], color='blue') #Uitlizando a biblioteca Seaborn que foi importada na primeira atividade (sns), 'y' deixamos na vertical o gráfico
#Definindo o intervalo do eixo Y
min_val = df[coluna_nome].min()
max_val = df[coluna_nome].max()
plt.yticks(np.arange(min_val, max_val + 10, step=10)) #De 10 em 10 unidades
plt.grid(axis='y', linestyle='--', alpha=0.7) #Adicionando linhas para facilitar a visualização
plt.title(f"Boxplot de {coluna_nome}\nQuantidade de Outliers: {quantidade_outliers}")
plt.xlabel(coluna_nome)
plt.show()
#Descrição solicitada
print(f"Variável: {coluna_nome}")
print(f"Total de registros: {df[coluna_nome].count()}") #Exibindo a quantidade registro válidos na coluna.
print(f"Outliers detectados: {quantidade_outliers}") #Exbindo os outliers que calculamos em len()
print(f"Intervalo aceitável: {limite_inf:.2f} a {limite_sup:.2f}")
print("-" * 90)
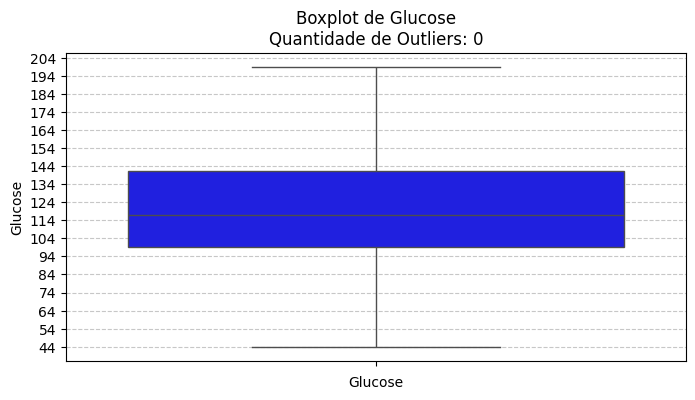
1
2
3
4
5
Variável: Glucose
Total de registros: 763
Outliers detectados: 0
Intervalo aceitável: 36.00 a 204.00
------------------------------------------------------------------------------------------
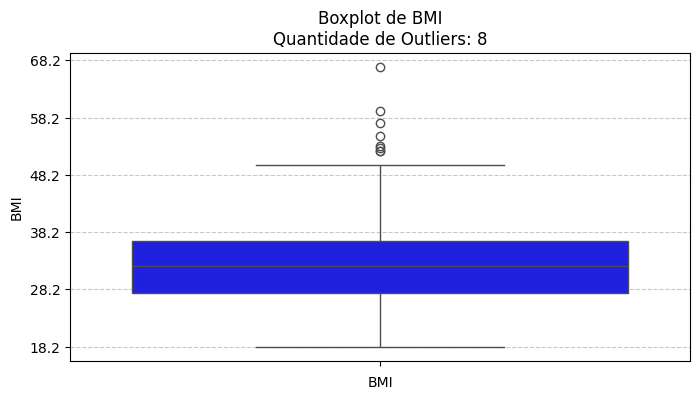
1
2
3
4
5
Variável: BMI
Total de registros: 757
Outliers detectados: 8
Intervalo aceitável: 13.85 a 50.25
------------------------------------------------------------------------------------------
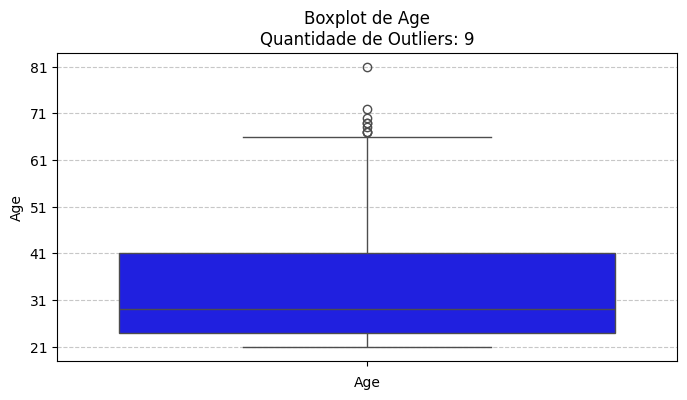
1
2
3
4
5
Variável: Age
Total de registros: 768
Outliers detectados: 9
Intervalo aceitável: -1.50 a 66.50
------------------------------------------------------------------------------------------
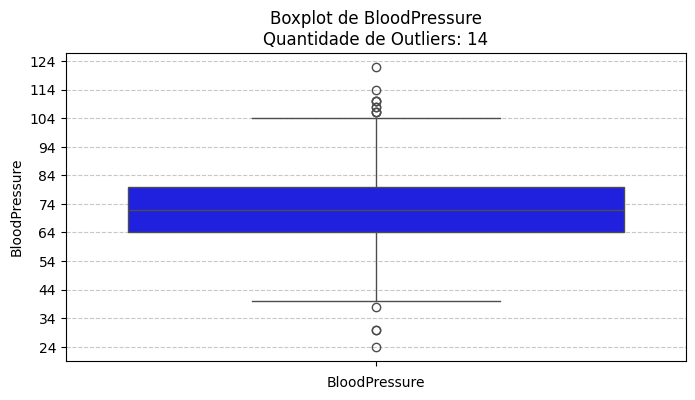
1
2
3
4
5
Variável: BloodPressure
Total de registros: 733
Outliers detectados: 14
Intervalo aceitável: 40.00 a 104.00
------------------------------------------------------------------------------------------
Criação de gráficos e análise
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
'''
6. Criar um gráfico de barras da variável Outcome usando value_counts().plot(kind='bar').
'''
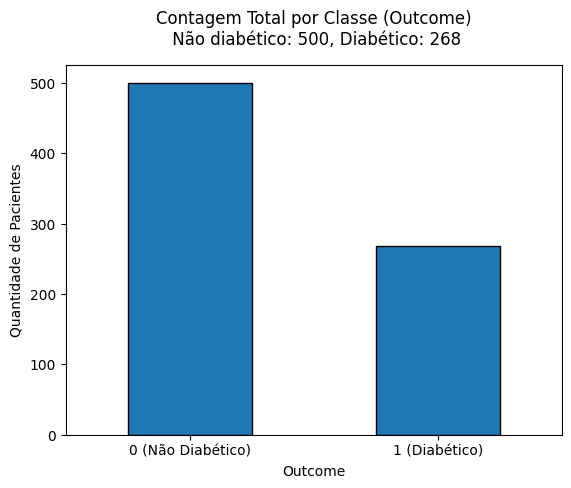
outcome_counts = df['Outcome'].value_counts() #contando os valores
#Separando os valores para exibi-los dentro do grafico
nao_diabetico = outcome_counts[0]
diabetico = outcome_counts[1]
outcome_counts.plot(kind='bar', edgecolor='black') # Inserindo barras e bordas
plt.title(f'Contagem Total por Classe (Outcome)\n Não diabético: {nao_diabetico}, Diabético: {diabetico}', pad=15) #Inserindo um título e valores, no título
plt.xticks(ticks=[0, 1], labels=['0 (Não Diabético)', '1 (Diabético)'], rotation=0) #Abaixo do eixo horizontal colocando legenda
plt.ylabel('Quantidade de Pacientes') #Eixo vertical
plt.show() #Exibindo gráfico
Comparação de médias
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
'''
7. Comparar médias de Glucose e BMI entre diabéticos e não diabéticos usando
groupby('Outcome').
'''
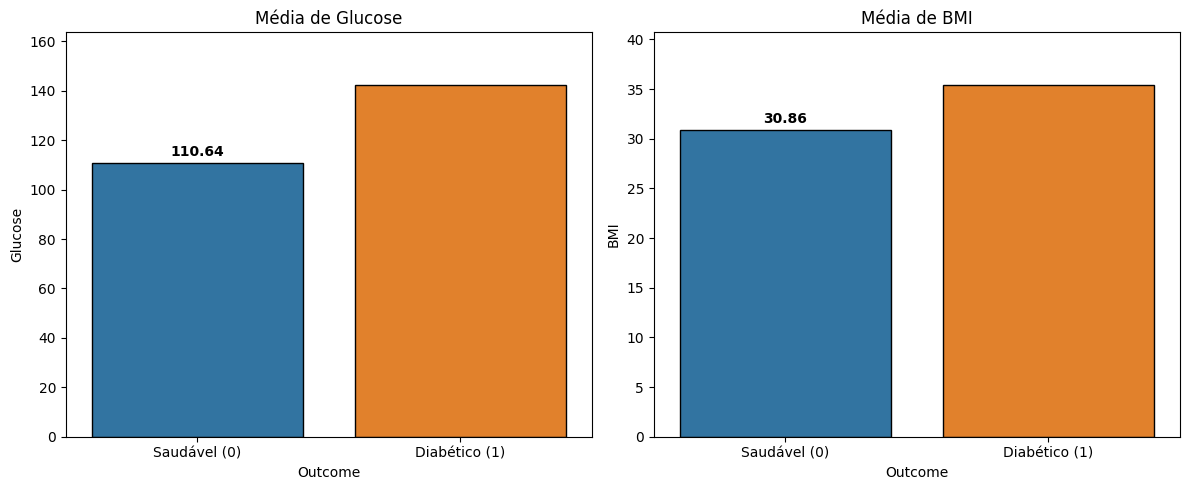
#Calculando as médias agrupadas por Outcome
df_medias = df.groupby('Outcome')[['Glucose', 'BMI']].mean()
#Criando a estrutura dos gráficos
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
#Definindo as colunas que serão utilizadas
colunas = ['Glucose', 'BMI']
#Percorre a lista fornecendo tanto o nome da coluna canto o índice
for i, col in enumerate(colunas):
sns.barplot(x=df_medias.index, y=df_medias[col], ax=axes[i],
hue=df_medias.index, legend=False, edgecolor='black') #'hue' para tratar o 'FutureWarning' que estava aparecendo na saída do programa
#Adicionando labels com os valores exatos
axes[i].bar_label(axes[i].containers[0], fmt='%.2f', padding=3, fontweight='bold')
#Definimos os ticks antes dos labels
axes[i].set_xticks([0, 1])
axes[i].set_xticklabels(['Saudável (0)', 'Diabético (1)'])
axes[i].set_title(f'Média de {col}')
axes[i].set_ylim(0, df_medias[col].max() * 1.15)
plt.tight_layout()
plt.show()
Criação scatterplots: Glucose × BMI e Age × BMI
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
'''
8. Criar scatterplots de Glucose × BMI e Age × BMI coloridos por Outcome.
'''
y = df['Outcome'] #Coluna que queremos prevê o valor
#Criando o gráfico de scatterplots
plt.figure(figsize=(5, 5))
plt.scatter(df.loc[y==0, 'Glucose'], df.loc[y==0, 'BMI'], label="Saudável") #Definindo 0 como saudável
plt.scatter(df.loc[y==1, 'Glucose'], df.loc[y==1, 'BMI'], label="Diabético") #Definindo 1 como diabético
#Definindo os eixos e título
plt.xlabel('Glucose')
plt.ylabel('BMI')
plt.title('Diagrama de dispersão entre Glucose e BMI')
plt.legend()
plt.show()
plt.figure(figsize=(5,5))
plt.scatter(df.loc[y==0, 'Age'], df.loc[y==0, 'BMI'], label="Saudável")
plt.scatter(df.loc[y==1, 'Age'], df.loc[y==1, 'BMI'], label="Diabético")
plt.xlabel('Age')
plt.ylabel('BMI')
plt.title('Diagrama de dispersão entre Age e BMI')
plt.legend()
plt.show()
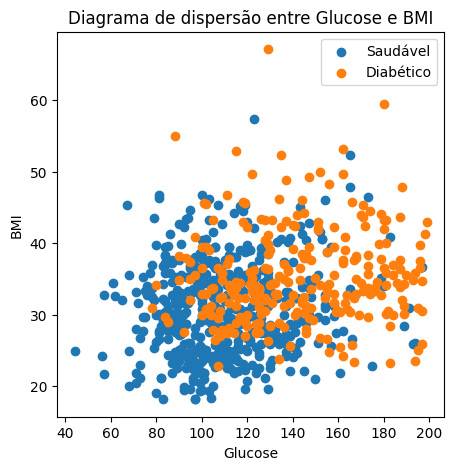
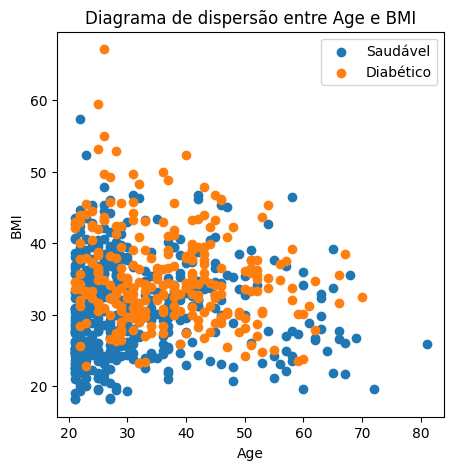
Interpretação da separação visual entre grupos, dos diagramas de dispersão acima.
Glucose x BMI
No gráfico Glucose x BMI, observa-se que a maioria dos dados se concentra na região central. Há uma maior predominância de casos diabéticos (laranja) em pessoas com glicose entre 100 e 130, sendo que a grande maioria possui BMI inferior a 50, apesar de ser comum diabéticos de 100 a 130 de glicose, é muito provavél que o indivíduo com glicose acima de 140 seja diabético. Já os indivíduos saudáveis (azul) apresentam, em sua maioria, glicose abaixo de 140 e BMI também inferior a 50.
AGE x BMI
No gráfico Age x BMI, a maioria dos indivíduos saudáveis tem menos de 33 anos, concentrando-se à esquerda do gráfico. Em contrapartida, os casos diabéticos estão mais dispersos ao longo do eixo da idade, embora a maioria ainda se encontre abaixo dos 50 anos.
Treinar uma regressão logística
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
'''
9. Treinar uma regressão logística:
'''
df.dropna(inplace=True) #Removendo os valores vazios, já tinhamos alterado para NaN
#Definindo as colunas que serão irão entrar no treinamento
X = df[['BMI', 'Age', 'Glucose', 'BloodPressure']]
#Definindo o alvo
y = df['Outcome']
X = StandardScaler().fit_transform(X) #realizando a padronização dos dados, aplica z-score
modelo = LogisticRegression() #criando o objeto classificador
modelo.fit(X, y) #realizando o treinamento
print("Acurácia: ", modelo.score(X, y)) #Aqui calculamos a acurácia e exibimos na tela
1
Acurácia: 0.7933673469387755
Interpretação da acurácia
A Regressão Logística obteve uma acurácia de 77%.
Isso significa que, ao combinar Glicose, IMC, Idade e Pressão Arterial, o modelo foi capaz de prever corretamente o diagnóstico na maioria dos casos, mostrando que essas variaveis(colunas) tem forte correlação.
Análise de PCA utilizando 3 parâmetros
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
'''
10. Executar uma análise de PCA utilizando 3 parâmetros.
'''
#Definindo quais colunas serão usadas
colunas_selecionadas = ['Glucose', 'BMI', 'Age']
#Removendo os valores vazios, já tinhamos alterado para NaN
df_filtrado = df.dropna(subset=colunas_selecionadas + ['Outcome']) #Removendo também da coluna 'Outcome'
X = StandardScaler().fit_transform(df_filtrado[colunas_selecionadas])
y = df_filtrado['Outcome']
pca = PCA(2) #Definindo a quantidade de componentes principais
Xp = pca.fit_transform(X)
v = pca.explained_variance_ratio_ * 100 #Cálculo de variância para mostrar a porcentagem em cada eixo
#Rotulandos dados no gráfico
plt.scatter(Xp[y==0, 0], Xp[y==0, 1], label="Saudável")
plt.scatter(Xp[y==1, 0], Xp[y==1, 1], label="Diabético")
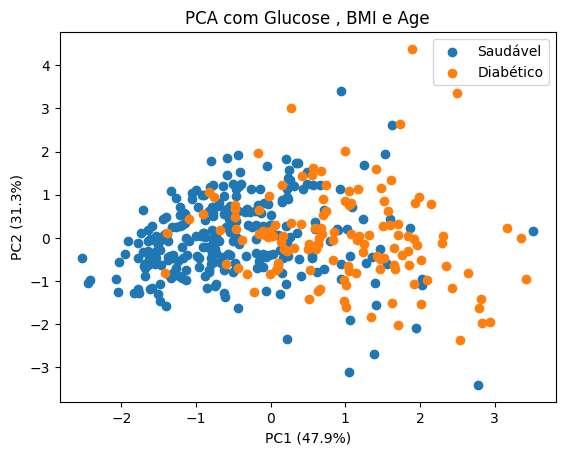
plt.title(f'PCA com {colunas_selecionadas[0]} , {colunas_selecionadas[1]} e {colunas_selecionadas[2]}') #Colocando no título as colunas
plt.xlabel(f'PC1 ({v[0]:.1f}%)') #Exibindo a porcentagem de variancia
plt.ylabel(f'PC2 ({v[1]:.1f}%)') #Exibindo a porcentagem de variancia
plt.legend()
plt.show()
#Criando uma tabela com os pesos de cada variável
loadings = pd.DataFrame(pca.components_.T, columns=['PC1', 'PC2'], index=colunas_selecionadas)
print('Mostrando o peso de cada variável no gráfico.')
print(loadings)
1
2
3
4
5
Mostrando o peso de cada variável no gráfico.
PC1 PC2
Glucose 0.677701 -0.083079
BMI 0.422247 0.857424
Age 0.602021 -0.507861
Comentários sobre o gráfico acima.
A análise de PCA demonstrou que as variáveis Glucose, BMI e Age conseguem explicar 78% da variabilidade dos pacientes. Existe uma separação visual clara no eixo PC1, onde o grupo saudável se concentra em valores negativos e o grupo diabético em valores positivos, confirmando que a combinação desses três fatores é um forte indicador para a presença da doença.